
Essa é uma síntese do método desenvolvido e aplicado no MapBiomas Solo para modelagem espacial da granulometria e espaço-temporal do estoque de carbono orgânico do solo no território brasileiro. A descrição detalhada dos dados, métodos e algoritmos será disponibilizada em breve.
1. Introdução
A terceira coleção (versão beta) do MapBiomas apresenta mapas anuais de estoque de carbono orgânico do solo (COS) no Brasil (1985-2024) com resolução espacial de 30m, expressos em toneladas por hectare (t/ha) para os primeiros 30cm de profundidade.
Uma das novidades da coleção é a ampliação da profundidade dos mapas estáticos de distribuição do tamanho de partículas (teor percentual de areia, silte e argila) e classe textural do solo (três sistemas de classificação) para até 100cm de profundidade, em camadas de 10cm de espessura.
A coleção também apresenta mapas estáticos inéditos de pedregosidade do solo. Esses mapas indicam profundidade (cm) na qual o volume de fragmentos grossos atinge 50% (pedregosidade dominante) e 90% (pedregosidade extrema), limitando-se à profundidade máxima de 100cm.
Os mapas foram desenvolvidos utilizando dados de solo de campo publicados no Repositório SoilData (http://soildata.mapbiomas.org/) e dezenas de variáveis preditoras disponíveis em bases públicas de dados espaciais. Os mapas de propriedades do solo podem ser acessados no módulo do Solo da plataforma do MapBiomas (https://plataforma.brasil.mapbiomas.org/), onde podem ser visualizados e descarregados para diferentes recortes territoriais, ambientais e administrativos.
Tabela 1. Mapas de propriedade do solo com resolução espacial de 30 m disponibilizados no módulo do MapBiomas Solo para o território brasileiro.
| Propriedade do solo | Definição | Tipo de variável | Camada do solo | Resolução temporal | Ano nominal¹ |
| Estoque de carbono orgânico do solo (COS) | Mapas de estoques de COS | Contínua (estoques de 0 a 255 t/ha) | 0 – 30 cm | Anual | Não se aplica |
| Granulometria | Mapas de teores (%) de areia, silte e argila | Contínua (teores de 0 a 100%) | 0-10, 10-20, 20-30, 30-40, 40-50, 50-60, 60-70, 70-80, 80-90 e 90-100 cm | Não se aplica | 1990 |
| Textura | Mapas de classes de texturas do solo | Categórica (cinco, oito e treze classes) | 0-10, 0-20, 20-40, 0-30, 30-60, e 60-100 cm | Não se aplica | 1990 |
| Pedregosidade | Mapas de profundidade até limiares de pedregosidade: dominante (volume > 50%) e extrema (volume > 90%) | Contínuo | 0-100 cm | Não se aplica | 1990 |
2. Conceito
Seguindo os princípios do mapeamento digital de solos, as propriedades do solo são modeladas utilizando algoritmos de aprendizado de máquina (machine learning) que estabelecem relações estatísticas entre amostras de solo coletadas em campo e variáveis preditora, as quais representam os fatores e processos de formação do solo.
As variáveis preditoras estáticas representam os fatores de formação que estruturam a variação espacial das propriedades do solo. Já as variáveis dinâmicas capturam mudanças ao longo do tempo, como variações climáticas e transformações no uso e cobertura da terra. As relações estatísticas computadas pelos modelos são utilizadas para estimar como as propriedades do solo variam no espaço e no tempo, resultando na geração de mapas estáticos e séries anuais para o período de 1985 a 2024.
Os algoritmos de aprendizado de máquina empregados – Random Forest e Gradient Tree Boosting – baseiam-se em conjuntos de árvores de regressão aleatorizadas. Essas árvores utilizam subconjuntos dos dados para processar as relações estatísticas entre as observações de campo e as variáveis preditoras. A variação espacial e temporal das propriedades do solo é estimada com base no consenso dessas árvores.
A principal diferença entre os dois algoritmos reside na forma como as árvores de regressão são combinadas. O Random Forest opera com árvores independentes cujos resultados são agregados pela média. Analogamente, é como se centenas de especialistas mapeassem a mesma área de forma autônoma, sendo o mapa final a média de suas interpretações individuais.
Em contrapartida, o Gradient Tree Boosting constrói as árvores de forma sequencial, onde cada nova árvore busca corrigir progressivamente os erros da anterior. Esse processo assemelha-se a centenas de especialistas aprimorando sucessivamente o trabalho uns dos outros até atingir o resultado final.
3. Amostras de treinamento
Os dados de solo foram obtidos de diversos estudos publicados no repositório SoilData (http://soildata.mapbiomas.org/). Após uma análise criteriosa, um conjunto selecionado de estudos foi utilizado para o mapeamento da granulometria (teores de argila, silte, areia e fragmentos grossos). Esses dados abrangem milhares de pontos distribuídos pelo território brasileiro, compreendendo múltiplas camadas de solo até a profundidade de 100 cm. Para lidar com a ausência de dados de fragmentos grossos em diversas amostras, os valores faltantes foram estimados por meio de funções de pedotransferência (PTFs). Antes da modelagem, as proporções de argila, silte, areia e fração grossa foram convertidas em “log-razões aditivas” (ALR) — log(areia/argila), log(silte/argila) e log(fração grossa/argila) — uma transformação matemática que assegura a consistência e estabilidade do modelo.
Para o mapeamento espaço-temporal do estoque de COS, foram selecionados conjuntos de dados que compreendem milhares de pontos e camadas de solo. Como a densidade do solo estava ausente em muitas amostras, utilizou-se funções de pedotransferência para estimar esses valores. Após o controle de qualidade, os dados aptos foram utilizados para o treinamento do modelo espaço-temporal. O estoque de COS foi calculado para cada camada seguindo a equação: teor de carbono × (1 – volume de fragmentos grossos) × densidade do solo × espessura da camada.

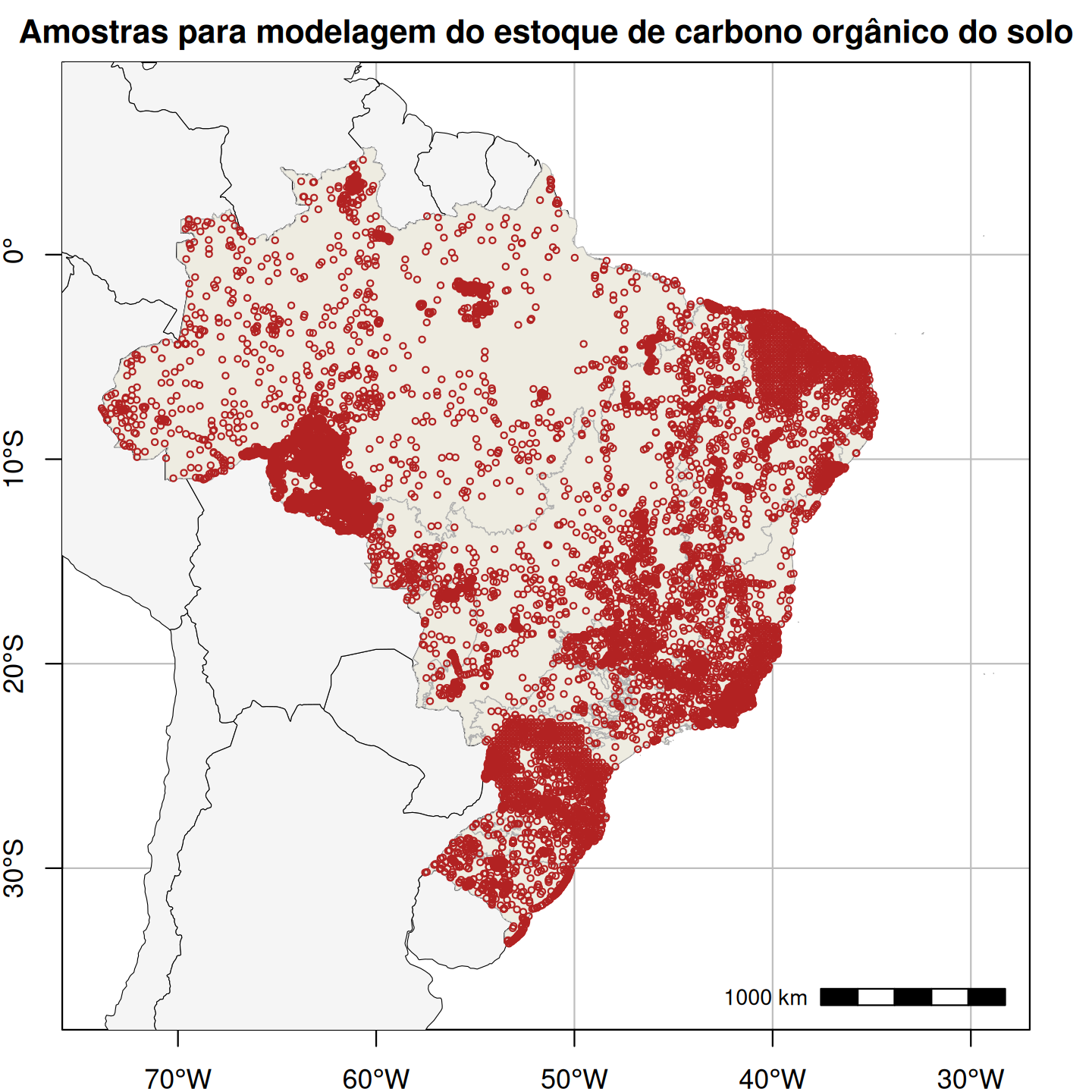
Figura 1. Distribuição espacial das amostras de treinamento obtidas no campo, utilizadas na modelagem espacial da granulometria do solo (esquerda; 15.798 pontos e 60.883 amostras) e espaço-temporal do estoque anual de carbono orgânico do solo (direita; 16.013 pontos e 31.047 camadas).
O processamento dos dados de solo de campo foi realizado localmente (R e Python) e na nuvem (Google Earth Engine). Os códigos estão disponíveis sob licença aberta no GitHub (https://github.com/mapbiomas/brazil-soil), e os dados estão publicados no SoilData sob licença CC-BY nos links: https://doi.org/10.60502/SoilData/OXSR2N (granulometria) e https://doi.org/10.60502/SoilData/IUZOAK (estoque de COS).
4. Variáveis preditoras
Dados raster e vetoriais (estáticos e dinâmicos) foram obtidos de bases abertas para todo o Brasil. No Google Earth Engine, as lacunas foram preenchidas e a resolução espacial padronizada em 30 m.
Variáveis multicategóricas — incluindo clima (Köppen), fitofisionomia, geologia, solos e biomas (IBGE) — foram convertidas em indicadores binários para assegurar compatibilidade algorítmica. Adicionalmente, geraram-se variáveis sintéticas combinando classes de solo, material de origem e compartimentos ambientais para capturar relações pedológicas complexas que variáveis isoladas não representariam.
Mapas de propriedades do solo foram agregados por profundidade (ex: granulometria para modelar carbono) e integrados às probabilidades da FAO/SoilGrids. O relevo foi representado pelo Geomorpho90m, enquanto a hidrologia e a dinâmica climática foram capturadas por indicadores de lâmina d’água agregados estatisticamente. Para incorporar o contexto espacial, calcularam-se distâncias geográficas a feições como areais e afloramentos rochosos.
Índices de vegetação (NDVI e EVI) do Landsat foram modelados com médias móveis ponderadas para representar os efeitos de longo prazo da biomassa no solo. Por fim, o efeito temporal do uso da terra foi representado pela evolução da idade de cada classe do MapBiomas Cobertura 10.0.
Tabela 2. Alguns exemplos de variáveis preditoras estáticas e dinâmicas usadas na modelagem da granulometria (133) e estoque anual de COS (126) associadas ao fator de estado ou vetor de mudança do solo que elas representam.
| Fator ou vetor | Variável preditora | Tipo de variável |
| Solo | Teor de areia, silte e argila 0-30cm Fonte: MapBiomas Solo, Coleção 3.0 | contínua; estática |
| Classificação pedológica (1º nível categórico) Fonte: IBGE | categórica; estática | |
| Probabilidade de ocorrência de classes de solo Fonte: SoilGrids 1.0 e FAO GBSmap | contínua; estática | |
| Clima | Classificação climática de Köppen Fonte: Alvares et al. (2013) | categórica; estática |
| Hidrologia; Mudança climática | Cobertura do solo com lâmina de água (ocorrência/ausência e frequência absoluta) Fonte: MapBiomas, Coleção 10.0 | contínua; dinâmica e estática |
| Organismos | Classificação da vegetação primária (fitofisionomia) Fonte: IBGE | categórica; estática |
| Permanência e mudança da cobertura e uso da terra | Idade da classe de cobertura e uso da terra Fonte: MapBiomas, Coleção 10.0 | contínua; dinâmica |
| Índices de vegetação como NDVI, SAVI e EVI Fonte: Imagens Landsat | contínua; dinâmica | |
| Degradação ou perda de organismos | Indicadores de degradação da vegetação nativa (distância de borda de uso antrópico) Fonte: MapBiomas Degradação, Coleção Beta 1.0 | contínua; dinâmica |
| Indicadores de ocorrência de fogo (ocorrência acumulada; frequência no período; anos desde o último fogo) Fonte: MapBiomas Fogo, Coleção 4.0 | contínua; dinâmica e estática | |
| Relevo | Variáveis morfométricas do terreno como declividade, índice topográfico composto e elevação Fonte: Geomorpho90m | contínua; estática |
| Geologia | Classificação da geologia (províncias estruturais) Fonte: IBGE | categórica; estática |
| Território ou posição espacial | Classificação territorial por bioma Fonte: IBGE | categórica; estática |
| Distância à feições espaciais (areais, afloramentos de rocha) | contínua; estática |
5. Modelagem e mapeamento
As matrizes de treinamento para os algoritmos de aprendizado de máquina foram geradas pelo cruzamento dos dados das amostras de solo com as variáveis preditoras. Em ambas as modelagens — granulometria e estoque de COS —, a profundidade da camada alvo foi incluída como variável preditora. O algoritmo Gradient Tree Boosting foi aplicado à modelagem espacial (2D) da granulometria, enquanto o Random Forest foi utilizado para a modelagem espaço-temporal-vertical (4D) do estoque de COS. A configuração ideal de hiperparâmetros e a seleção do conjunto final de variáveis foram determinadas por técnicas de reamostragem, como bootstrap e validação cruzada..
Para a granulometria, foram treinados três modelos Gradient Tree Boosting para cada uma das dez camadas de solo, correspondendo às razões log-aditivas: log(areia/argila), log(silte/argila) e log(fração grossa/argila), totalizando 30 modelos. Estes foram aplicados para gerar mapas de razões log-aditivas na profundidade de 0 a 100 cm (intervalos de 10 cm), com predições no ponto central de cada camada (ex: 5, 15, 25 cm). Posteriormente, os resultados foram convertidos para a escala original de conteúdo percentual de argila, silte e areia (referentes à terra fina) e de fração grossa (referente ao solo inteiro). As frações foram então agregadas para profundidades de interesse agronômico e ambiental (0–10, 0–20, 20–40, 0–30, 30–60 e 60–100 cm) via álgebra de mapas e classificadas em três esquemas texturais distintos (cinco, oito e treze classes).
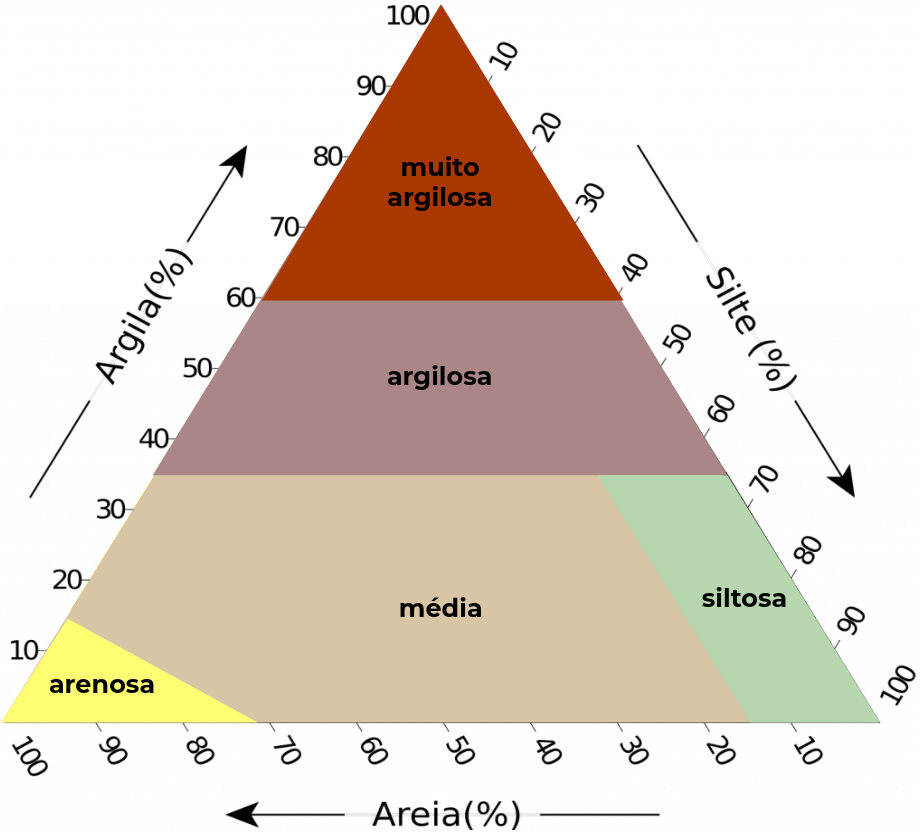
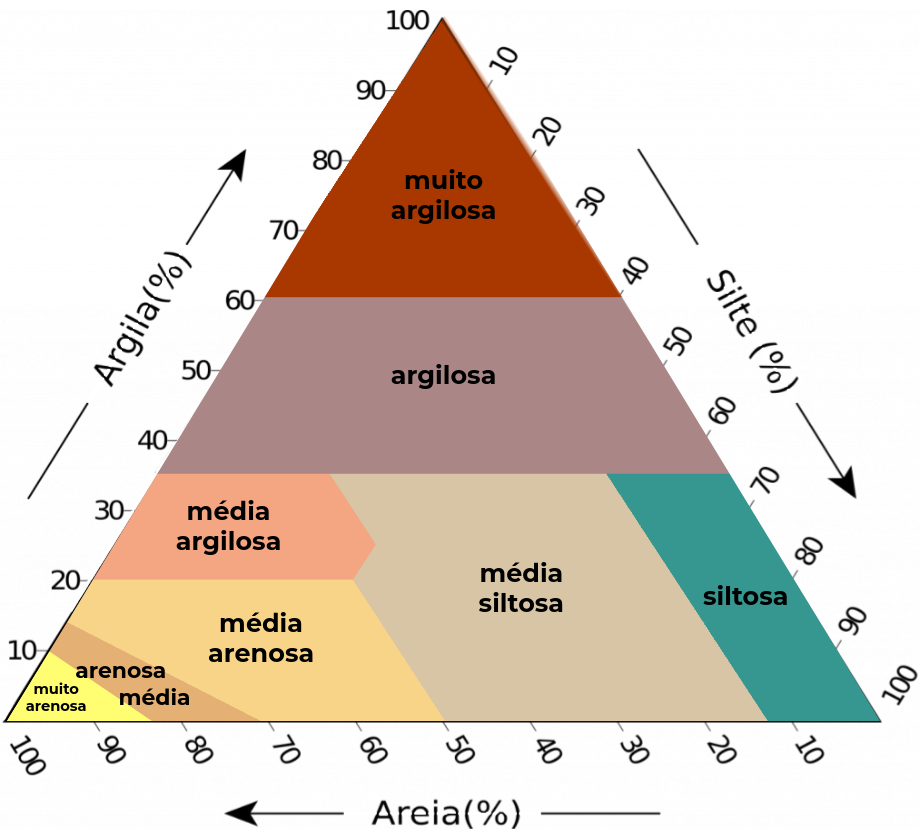
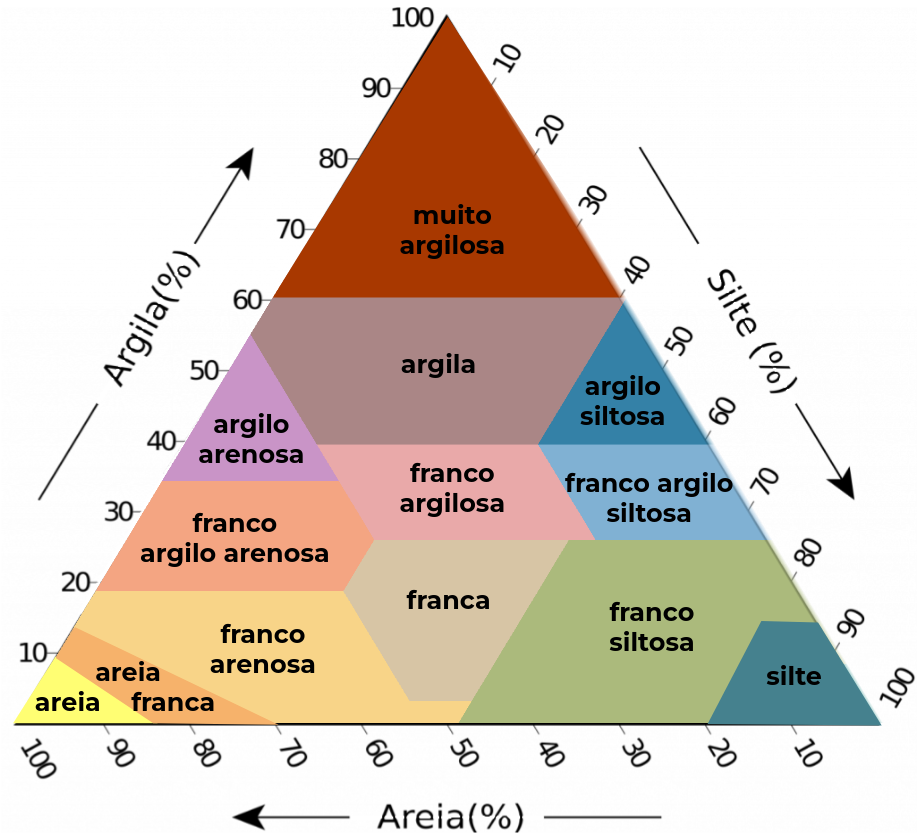
Figura 2. Esquemas de classificação da textura do solo com cinco (esquerda), oito (centro) e treze (direita) classes em função do conteúdo de argila, silte e areia (triângulo textural).
Os teores da fração grossa foram convertidos em valores volumétricos, utilizando-se a densidade do solo e da fração grossa. A partir desses dados, geraram-se mapas de pedregosidade identificando as profundidades, ao longo do perfil (0–100 cm), em que o volume da fração grossa excede os limiares de 50% (pedregosidade dominante) e 90% (pedregosidade extrema). Os mapas resultantes limitam-se à profundidade de 100 cm.
Para o estoque de carbono orgânico do solo (COS), um único modelo Random Forest foi treinado para estimar o estoque cumulativo desde a superfície até a profundidade inferior de cada camada. Para gerar a série histórica (1985–2024), o modelo foi aplicado repetidamente, substituindo-se as covariáveis dinâmicas pelos dados respectivos de cada ano, com predições finais para a profundidade de referência de 30 cm. Essa abordagem permitiu capturar mudanças temporais no estoque de COS sem a necessidade de incluir o ano cronológico como um preditor numérico.
A modelagem dos dados pontuais foi realizada localmente em R e Python, enquanto o treinamento e a predição espacial foram processados na nuvem via Google Earth Engine. Os códigos estão disponíveis sob licença aberta no GitHub (https://github.com/mapbiomas/brazil-soil). Os dados estão sob licença Creative Commons Atribuição CC-BY nos repositórios: https://doi.org/10.58053/MapBiomas/9ORUPF (granulometria), https://doi.org/10.58053/MapBiomas/2LUSVQ (estoque de carbono) e https://doi.org/10.58053/MapBiomas/1JGPIU (pedregosidade).
Acesse o documento de legenda da Coleção 3 do MapBiomas Solo aqui