
Aqui detalhamos a metodologia do MapBiomas Brasil passo a passo. Para cada classe, série de anos e país existem peculiaridades e características específicas que podem ser conferidas em detalhes no ATBD (Documento Base Teórico do Algoritmo) e seus apêndices.
Mosaico Anuais
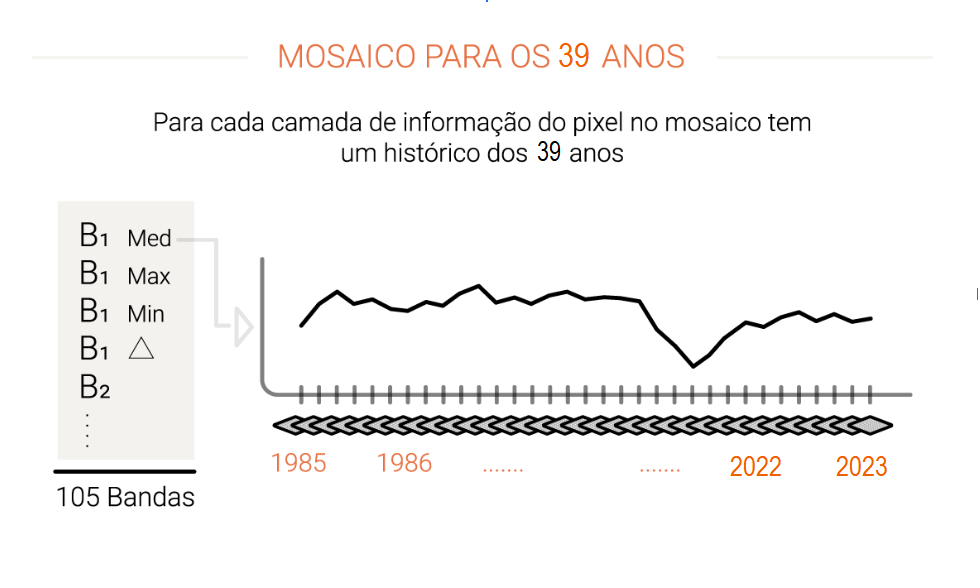
Tudo começa com as imagens do satélite Landsat, com resolução de 30 metros, disponíveis gratuitamente na plataforma Google Earth Engine e com uma série temporal de mais de 30 anos. São necessárias 380 imagens Landsat para cobrir o Brasil, cada uma delas com dezenas de milhões de pixels: no total, são mais de 9 bilhões de pixels de 30 x 30 metros para perfazer todo o país. Estes pixels são as unidades de trabalho do MapBiomas. As imagens podem conter nuvens, fumaça e outros artefatos que podem “sujá-las”. Para produzir uma imagem limpa, são selecionados os pixels sem nuvem dentre as imagens disponíveis para o período selecionado. Para cada um destes pixels são extraídas métricas que explicam o comportamento do pixel naquele ano. Isso é feito com cada uma das 7 bandas espectrais do satélite, assim como para as frações e índices espectrais calculados. Por exemplo para a Banda 1 é coletado a mediana dos valores da banda no período, o valor máximo, o valor mínimo a amplitude de variação. Ao final cada pixel carrega até 105 camadas de informação para um ano.
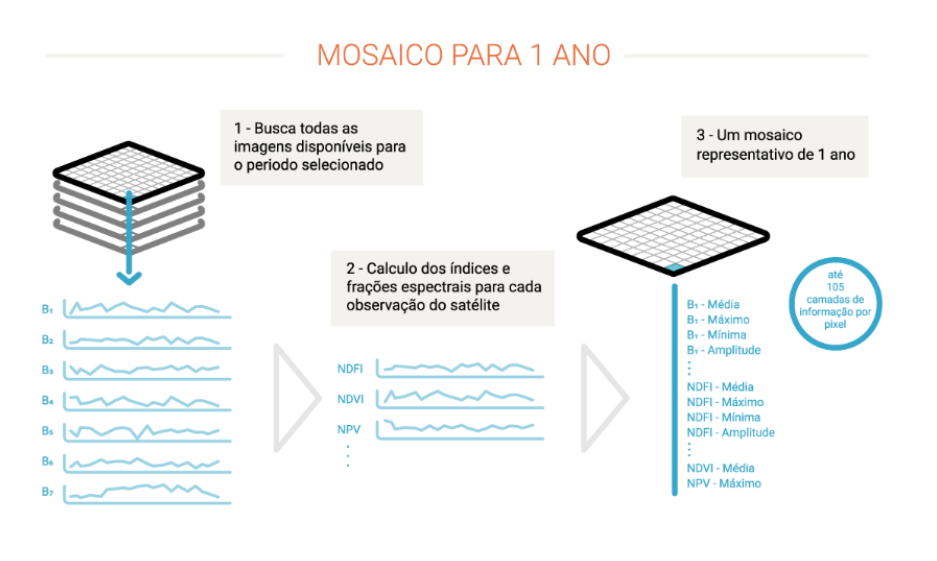
Para cada ano é montado um mosaico que cobre o Brasil representando o comportamento de cada pixel através de 105 métricas ou camadas de informação. Este conjunto de mosaicos é salvo como uma coleção de dados (Asset) dentro da plataforma do Google Earth Engine. Estes mosaicos serão utilizados em duas formas principais. Primeiro como fonte de parâmetros para o algoritmo classificar as imagens (ver próximo passo). É deste mosaico também que sai a composição RGB que permite visualizar a imagem de fundo na plataforma MapBiomas. Esta composição também é utilizada para a coleta de amostras de treinamento e avaliação de acurácia por interpretação visual.
Classificação
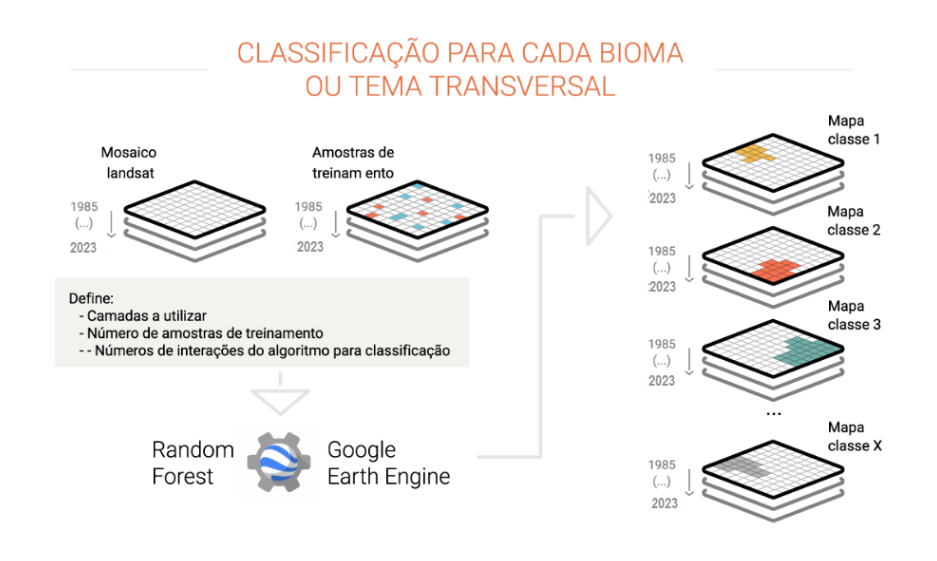
A partir dos mosaicos de imagens, as equipes de cada bioma e de cada tema transversal produzem um mapa de cada classe de cobertura e uso do solo (floresta, campo, agricultura, pastagem, área urbana, água, etc). Para isso, os analistas do MapBiomas utilizam um classificador automático chamado de “random forest”, que roda na nuvem de processadores da Google. Esse sistema é baseado em aprendizado de máquina: para cada tema a ser classificado, as máquinas são “treinadas” com amostras dos alvos a serem classificados. Estas amostras são obtidas por meio de mapas de referência, geração de mapas de classes estáveis das séries anteriores do MapBiomas e por coleta direta por interpretação visual das imagens Landsat. A classificação é feita para cada um dos anos da série, podendo ser salvas como um único mapa por classe onde cada pixel tem número de camadas correspondente ao número de anos da série histórica analisada.
Filtros
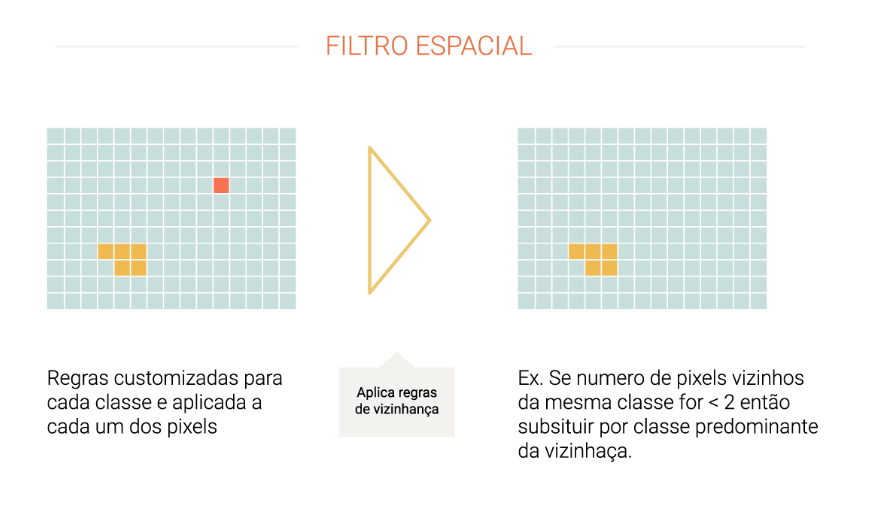
O filtro espacial visa ampliar a consistência espacial dos dados, eliminando pixels isolados ou de borda. São definidas regras de vizinhança que podem levar a alteração da classificação do pixel. Por exemplo, um pixel que tenha menos de dois dos nove pixels vizinhos na mesma classe será reclassificado para a classe predominante na vizinhança. Cada pixel em cada ano e para cada classe de uso passa por este processo de filtragem espacial.
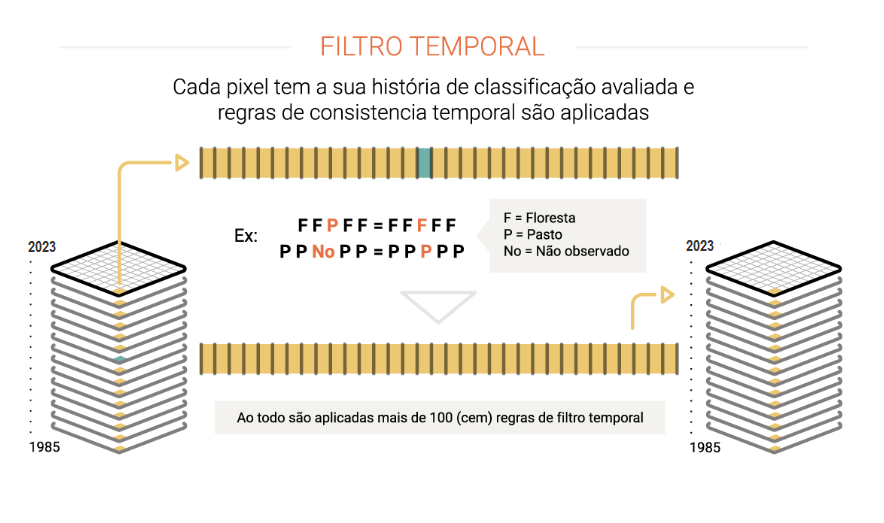
Para reduzir inconsistências temporais, em especial as mudanças de cobertura e uso impossíveis ou não permitidas (ex. Florestal Natural > Não Floresta > Floresta Natural) e corrigir falhas por excesso de nuvem ou falta de dados, são aplicadas regras de filtro temporal. Para cada bioma, tema ou região podem ter regras específicas de filtro temporal. No total na Coleção 3 foram aplicadas mais de uma centena de regras. O filtro temporal é aplicado em cada pixel analisando todos os anos da Coleção (ex. Coleção 3 foram 33 anos).
Integração
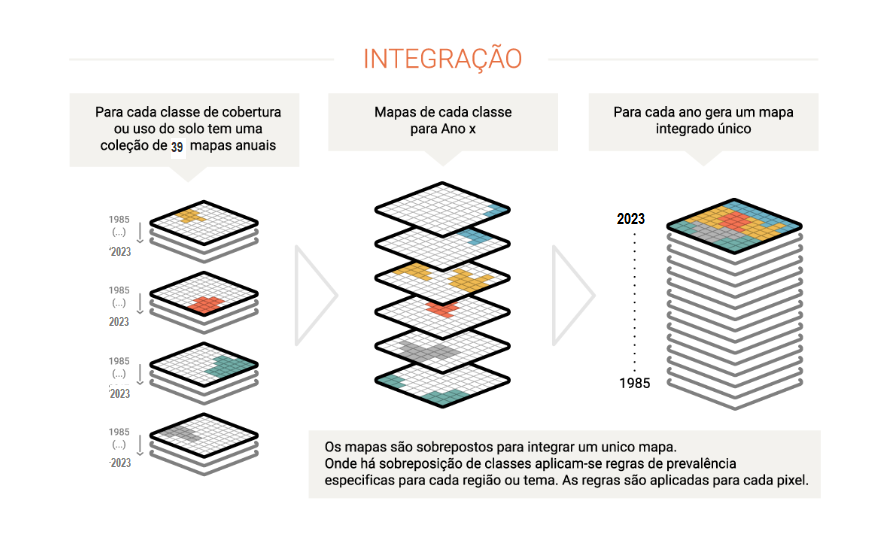
Nesta etapa, os mapas de cada classe são integrados em um único mapa, que representa a cobertura e o uso da terra de todo território para cada ano. São aplicadas regras de prevalência: assim, caso um mesmo pixel seja classificado em dois mapas de classes distintas, é possível definir a qual pertence no mapa final. As regras de prevalência podem variar de acordo com as peculiaridades dos biomas, temas ou regiões. A integração é feita para cada ano da série e gera um mapa integrado para cada ano, geralmente salva como um único ASSET com o número de camadas anuais do período analisado. O mapa integrado passa por mais uma etapa de filtro espacial para limpar as bordas e pixels soltos como consequência do processo de integração.
Mapas de Transição
Para entender as mudanças na cobertura e uso do solo são produzidos mapas com as transições das classes entre diferentes pares de anos selecionados. Assim é possível visualizar o dinamismo do território, e responder a perguntas como quanto de floresta virou pastagem de um ano para outro, por exemplo, entre outras alterações na paisagem. Mapas de transição são produzidos pixel a pixel e após finalizados também passam por um filtro espacial para eliminar pixels de transição isolados ou de borda. A partir destes mapas são construídas as matrizes de transição para cada bioma, estado, município e os demais cortes territoriais disponíveis na plataforma MapBiomas.