
Here, we detail the methodology of MapBiomas Brazil step by step. For each class, series of years, and country, there are specific peculiarities and characteristics that can be reviewed in detail in the ATDB (Algorithm Theoretical Basis Document) and its appendices.
Annual Mosaics
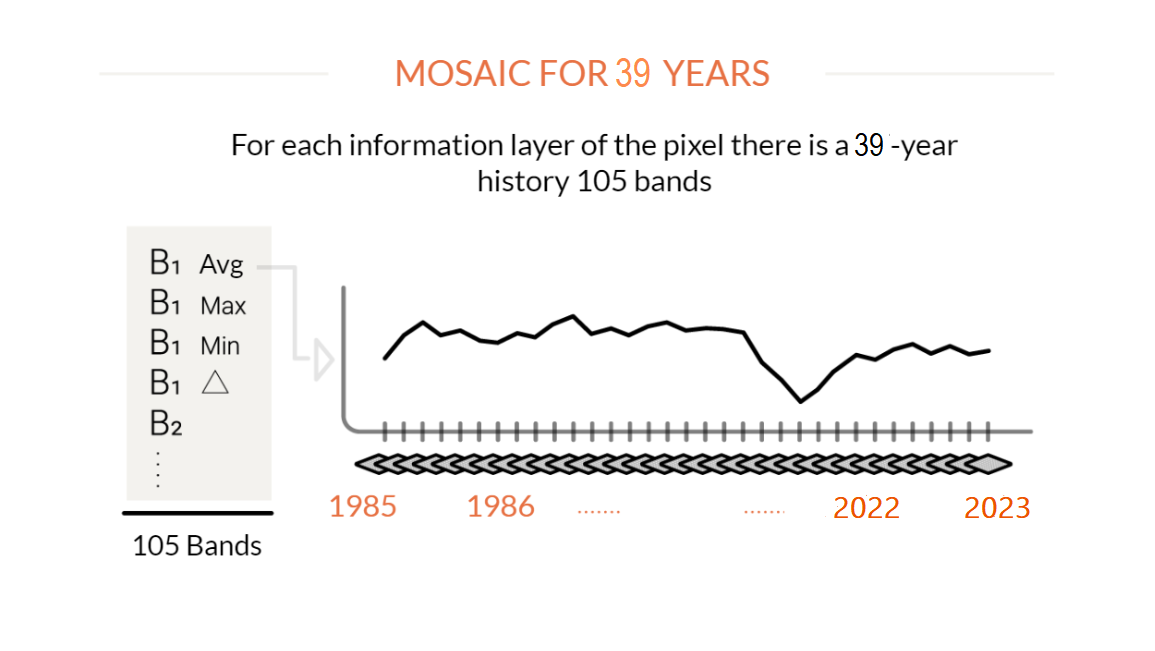
It all starts with Landsat satellite images, with a 30-meter resolution, available for free on the Google Earth Engine platform and with a time series of over 30 years. 380 Landsat images are needed to cover Brazil, each with tens of millions of pixels: in total, there are over 9 billion 30 x 30 meter pixels to cover the entire country. These pixels are the working units of MapBiomas. The images may contain clouds, smoke, and other artifacts that can "pollute" them. To produce a clean image, cloud-free pixels are selected from the available images for the chosen period. For each of these pixels, metrics are extracted that explain the behavior of the pixel for that year. This is done for each of the 7 spectral bands of the satellite, as well as for the calculated spectral fractions and indices. For example, for Band 1, the median value, maximum value, minimum value, and range of variation are collected. In the end, each pixel carries up to 105 layers of information for a year.
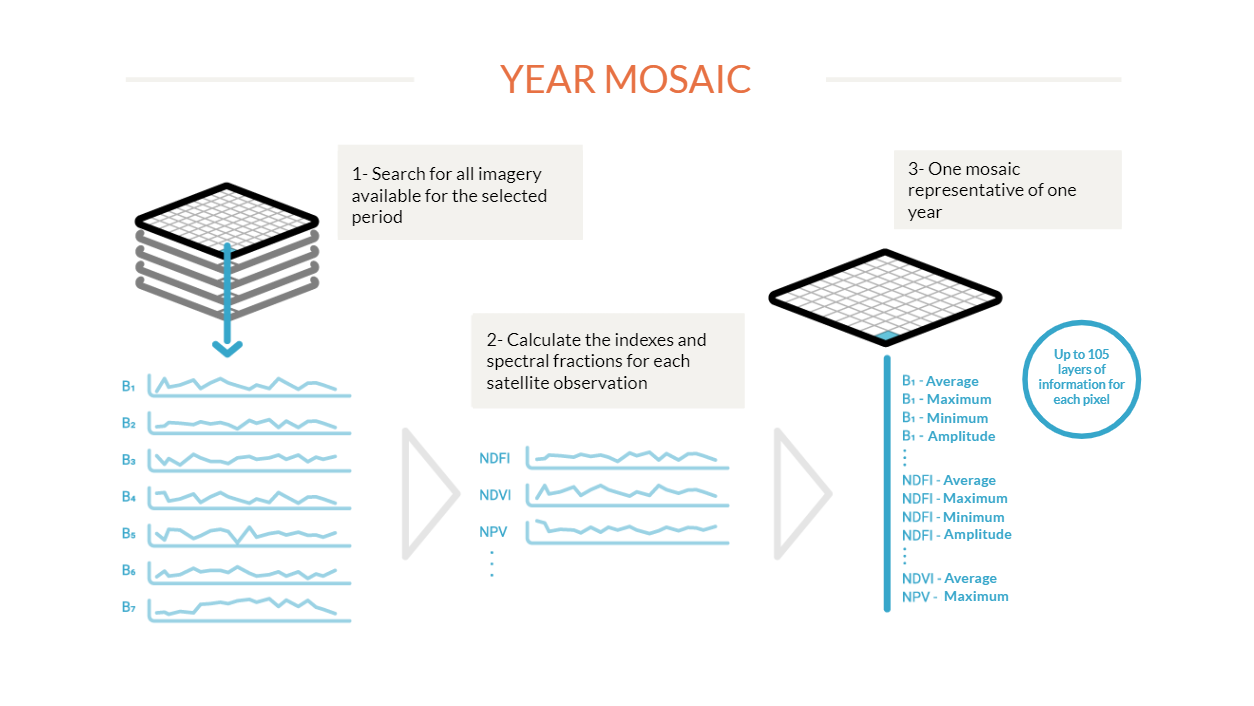
For each year a mosaic covering Brazil is set up representing the behavior of each pixel through 105 metrics or layers of information. This mosaic set is saved as a collection of data (Asset) within the Google Earth Engine platform. These mosaics will be used in two main ways. First as source parameters for the algorithm to produce classification (see next step). It is also from this mosaic that RGB composition is derived allowing to visualization of the background image in the platform MapBiomas. This composition is also used for the collection of training samples and samples for assessment of accuracy by visual interpretation.
Classification
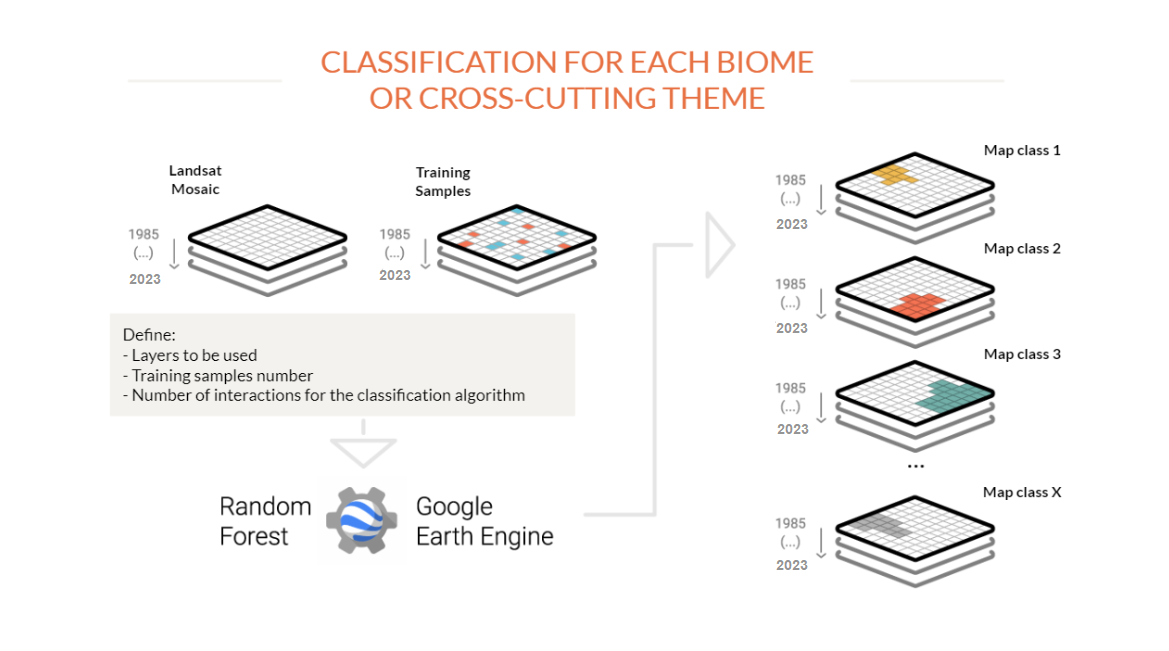
From the image mosaics, the teams for each biome and each cross-cutting theme produce a map for each land cover and land use class (forest, grassland, agriculture, pasture, urban area, water, etc.). To achieve this, MapBiomas analysts use an automatic classifier called "random forest," which runs on Google's cloud processors. This system is based on machine learning: for each theme to be classified, the machines are "trained" with samples of the targets to be classified. These samples are obtained through reference maps, generation of stable class maps from previous MapBiomas series, and direct collection through visual interpretation of Landsat images. The classification is done for each year in the series and can be saved as a single map per class, where each pixel has a number of layers corresponding to the number of years in the historical series analyzed.
Filtros
The spatial filter aims to increase the spatial consistency of the data by eliminating isolated or border pixels. Neighborhood rules are defined that can lead to a change in pixel classification. For example, a pixel that has less than two out of the nine neighboring pixels in the same class will be reclassified to the predominant class in the neighborhood. Each pixel in each year and for each class of use is subjected to spatial filtering.

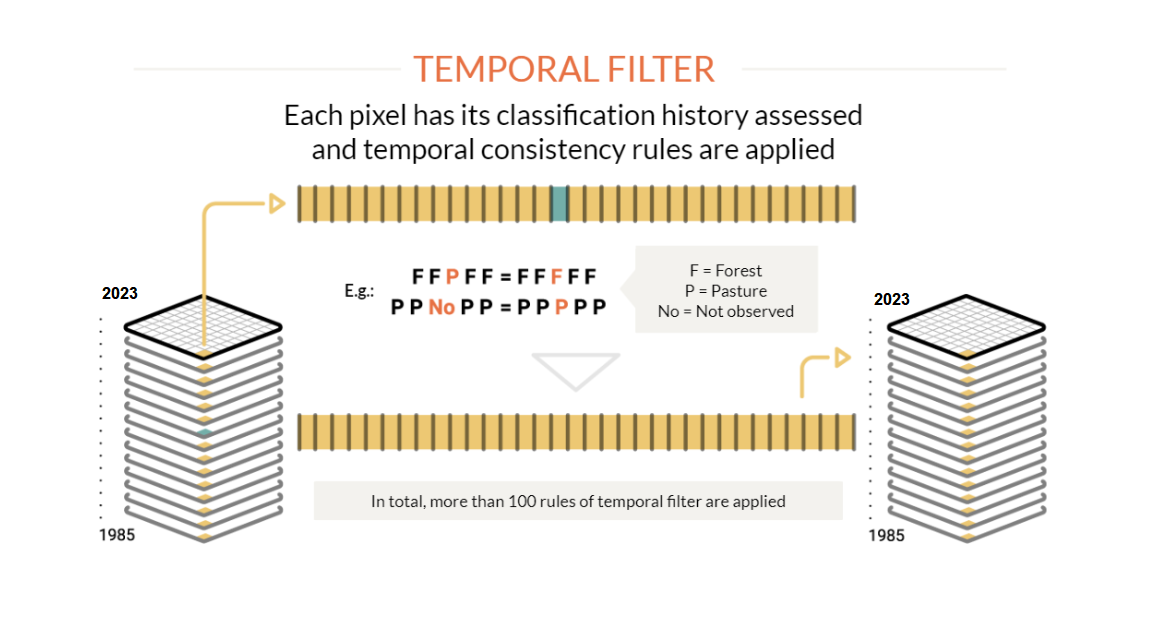
To reduce temporal inconsistencies, especially changes in land cover and use that are impossible or not allowed (e.g., Natural Forest > Non-Forest > Natural Forest) and to correct issues due to excess clouds or lack of data, temporal filtering rules are applied. For each biome, theme, or region, there may be specific temporal filtering rules. In total, Collection 3 applied over a hundred rules. The temporal filter is applied to each pixel by analyzing all the years in the collection (e.g., Collection 3 covered 33 years).
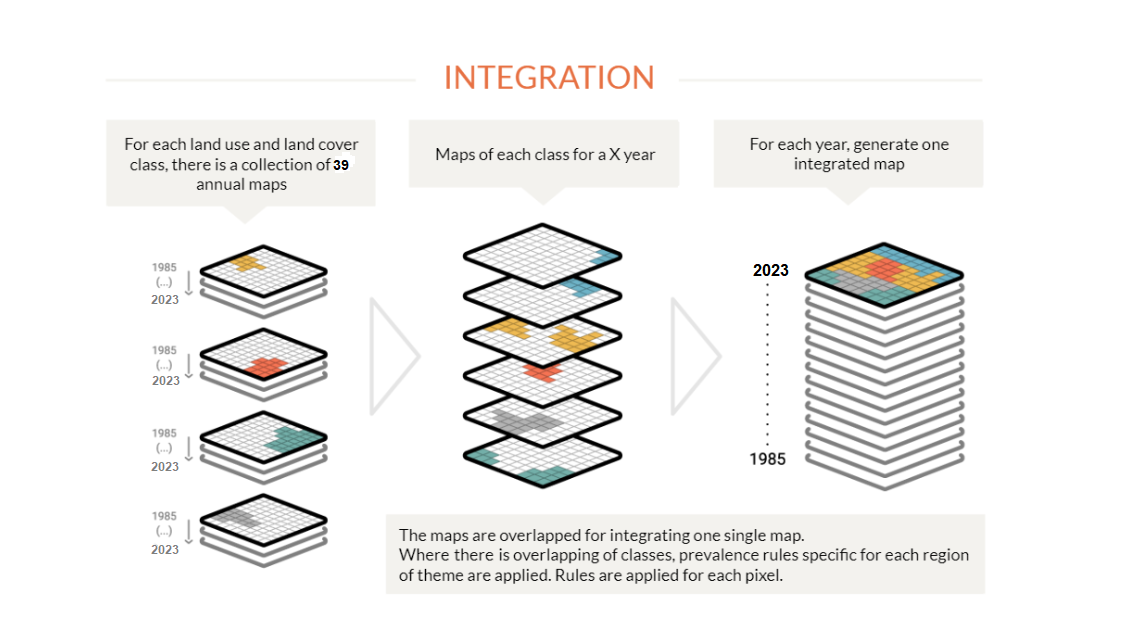
Integration
In this step, the maps of each class are integrated into a single map, which represents the coverage and land use of each territory for each year. Prevalence rules are applied: Thus, if the same pixel is classified into two distinct class maps, it is possible to define which one belongs to the final map. The prevalence rules may vary according to the peculiarities of the biomes, themes or regions. The integration is done for each year of the series and generates an integrated map for each year usually saved as a single ASSET with the number of annual layers of the period analyzed. The integrated map goes through a further step of spatial filtering to clean the edges and loose pixels as a consequence of the integration process.
Transition Maps
To understand changes in land cover and use, maps are produced showing the transitions between different pairs of selected years. This allows visualization of the dynamism of the territory and answers questions such as how much forest turned into pasture from one year to the next, among other landscape changes. Transition maps are produced pixel by pixel and, once completed, they also undergo a spatial filter to remove isolated or edge transition pixels. From these maps, transition matrices are constructed for each biome, state, municipality, and other territorial divisions available on the MapBiomas platform.